Configuring Models
Hermes uses two kinds of model slots:
- Main model — what the agent thinks with. Every user message, every tool-call loop, every streamed response goes through this model.
- Auxiliary models — smaller side-jobs the agent offloads. Context compression, vision (image analysis), web-page summarization, approval scoring, MCP tool routing, session-title generation, and skill search. Each has its own slot and can be overridden independently.
This page covers configuring both from the dashboard. If you prefer config files or the CLI, jump to Alternative methods at the bottom.
Nous Portal provides 300+ models under one subscription. On a fresh install, run hermes setup --portal to log in and set Nous as your provider in one command. Inspect what's wired up with hermes portal info.
- Portal subscribers also get 10% off token-billed providers.
model: schema — empty string vs. mappingOn a brand-new install the bundled default config has model: "" (an empty string sentinel meaning "not configured yet"). The first time you run hermes setup or hermes model, that key is upgraded in-place to a mapping with provider, default, base_url, and api_mode sub-keys — the shape shown throughout this page and in profiles.md / configuration.md. If you ever see an empty string in config.yaml, run hermes model (or click Change in the dashboard) and Hermes will write the dict form for you.
The Models page
Open the dashboard and click Models in the sidebar. You get two sections:
- Model Settings — the top panel, where you assign models to slots.
- Usage analytics — ranked cards showing every model that ran a session in the selected period, with token counts, cost, and capability badges.
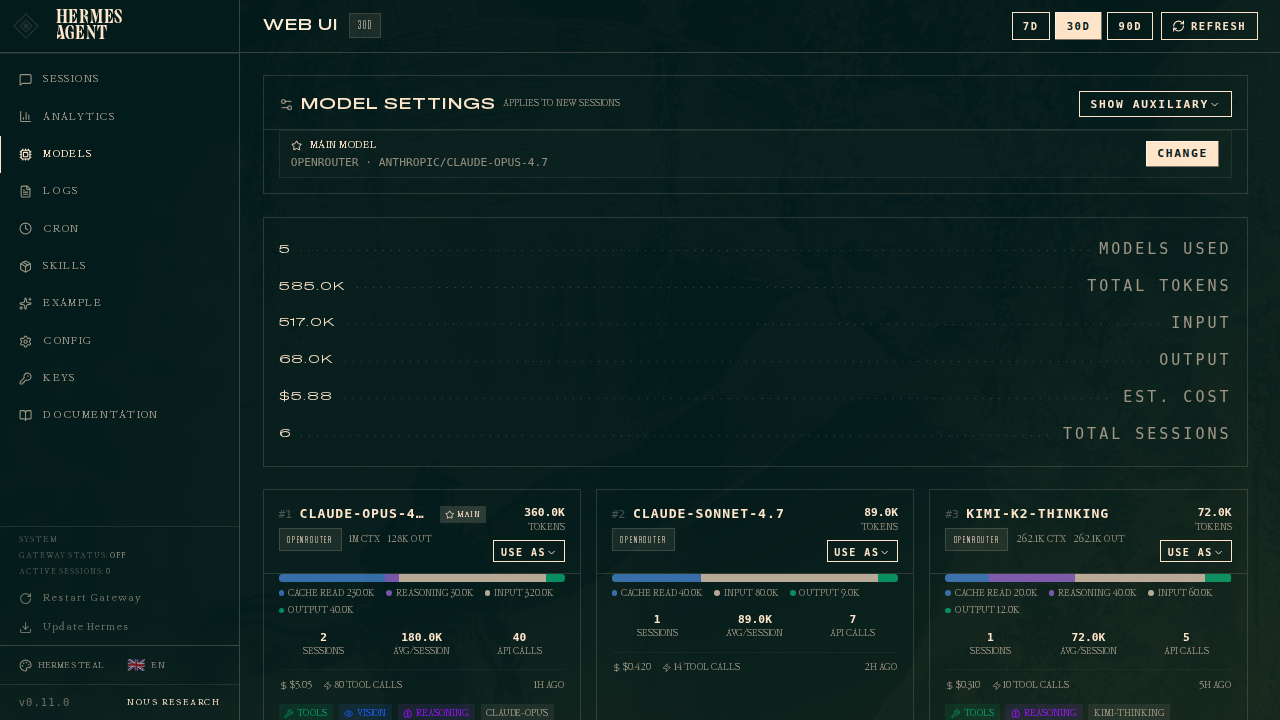
The top card is the Model Settings panel. The main row always shows what the agent will spin up for new sessions. Click Change to open the picker.
Setting the main model
Click Change on the Main model row:
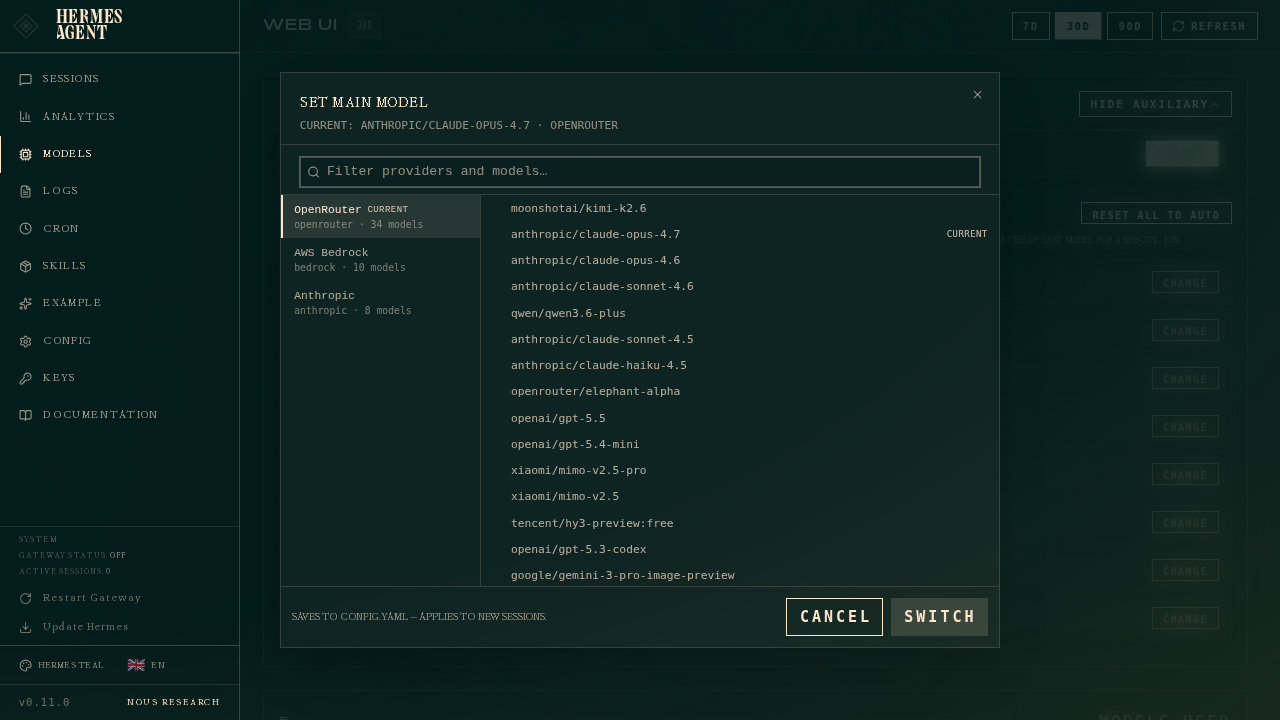
The picker has two columns:
- Left — authenticated providers. Only providers you've set up (API key set, OAuth'd, or defined as a custom endpoint) show up here. If a provider is missing, head to Keys and add its credential.
- Right — the curated model list for the selected provider. These are the agentic models Hermes recommends for that provider, not the raw
/modelsdump (which on OpenRouter includes 400+ models including TTS, image generators, and rerankers).
Type in the filter box to narrow by provider name, slug, or model ID.
Pick a model, hit Switch, and Hermes writes it to ~/.hermes/config.yaml under the model section. This applies to new sessions only — any chat tab you already have open keeps running whatever model it started with. To hot-swap the current chat, use the /model slash command inside it.
Mid-session switches and context warnings
When you switch models inside an active session (Herm TUI model picker, hermes CLI, or /model on Telegram/Discord), Hermes estimates whether your next message will run preflight context compression against the new model's window. If the session is already near or above that model's compression threshold (see Context Compression), the switch reply includes a warning — the same warning_message path used for expensive-model notices. The switch still applies immediately; compression runs on the first user message after the switch, before the model answers.
Prompt caches are keyed to the model serving the request, so any mid-conversation model change — an explicit /model switch, an automatic fallback, or a credential-pool rotation onto a different account — means the next message re-reads the entire conversation at full input-token price instead of the cached (~75–90% discounted) rate. On a long session this one-time re-read can dwarf the per-token difference between the two models. Switch when you need to, but prefer doing it early in a conversation or right after starting a fresh session.
Setting auxiliary models
Click Show auxiliary to reveal the 11 task slots:
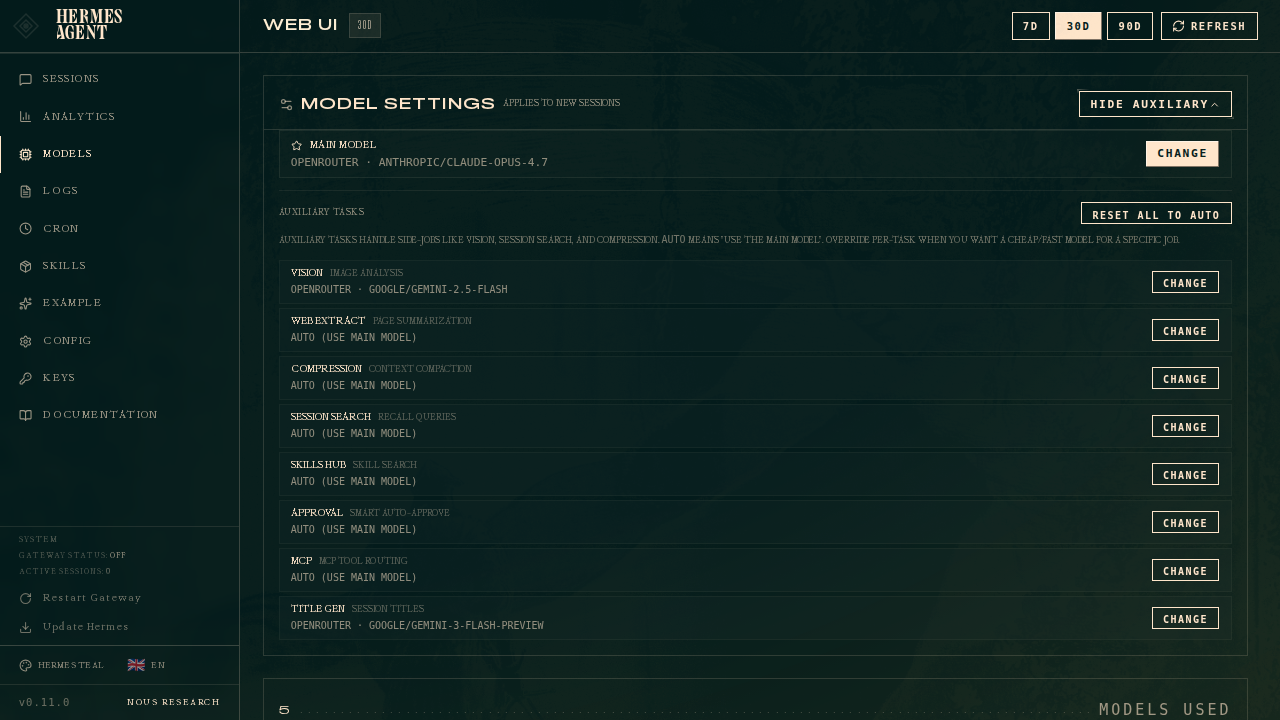
Every auxiliary task defaults to auto — meaning Hermes tries your main model for that job too. If that route is unavailable or hits a capacity-style failure, auto follows any task-specific auxiliary.<task>.fallback_chain, then the main fallback_providers / fallback_model chain, then Hermes' built-in auxiliary discovery chain. Override a specific task when you want a cheaper or faster model for a side-job.
Common override patterns
| Task | When to override |
|---|---|
| Title Gen | Almost always. A $0.10/M flash model writes session titles as well as Opus. Default config sets this to google/gemini-3-flash-preview on OpenRouter. |
| Vision | When your main model lacks vision support. Point it at google/gemini-2.5-flash or gpt-4o-mini. |
| Compression | When you're burning reasoning tokens on Opus/M2.7 just to summarize context. A fast chat model does the job at 1/50th the cost. |
| Approval | For approval_mode: smart — a fast/cheap model (haiku, flash, gpt-5-mini) decides whether to auto-approve low-risk commands. Expensive models here are waste. |
| Web Extract | When you use web_extract heavily. Same logic as compression — summarization doesn't need reasoning. |
| Skills Hub | hermes skills search uses this. Usually fine at auto. |
| MCP | MCP tool routing. Usually fine at auto. |
| Triage Specifier | Routes the Kanban triage specifier (hermes kanban specify) that expands a rough one-liner into a concrete spec. A cheap, capable model works well. |
| Kanban Decomposer | Routes Kanban task decomposition — splits a triage task into a graph of child tasks for specialist profiles. |
| Profile Describer | Routes profile-description generation (hermes profile describe --auto / the dashboard auto-generate button). Short, cheap call. |
| Curator | Routes the curator skill-usage review pass. Can run for minutes on reasoning models, so a cheaper aux model is often worthwhile. |
Per-task override
Click Change on any auxiliary row. Same picker opens, same behavior — pick provider + model, hit Switch. The row updates to show provider · model instead of auto (use main model).
Reset all to auto
If you've over-tuned and want to start over, click Reset all to auto at the top of the auxiliary section. Every slot goes back to using your main model.
The "Use as" shortcut
Every model card on the page has a Use as dropdown. This is the fast path — pick a model you see in your analytics, click Use as, and assign it to the main slot or any specific auxiliary task in one click:
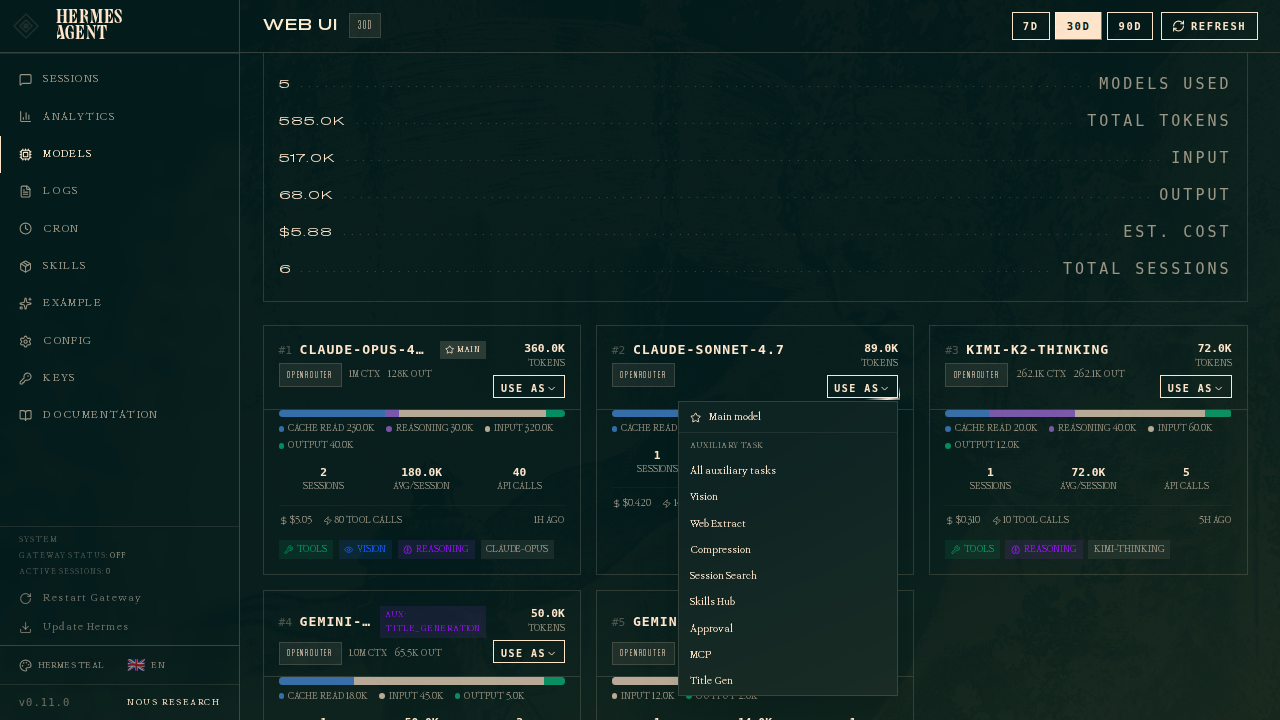
The dropdown has:
- Main model — same as clicking Change on the main row.
- All auxiliary tasks — assigns this model to all 11 aux slots at once. Useful when you just want every side-job on a cheap flash model.
- Individual task options — Vision, Web Extract, Compression, etc. The currently-assigned model for each task is marked
current.
Cards are badged with main or aux · <task> when they're currently assigned to something — so you can see at a glance which of your historical models are wired in where.
What gets written to config.yaml
When you save via the dashboard, Hermes writes to ~/.hermes/config.yaml:
Main model:
model:
provider: openrouter
default: anthropic/claude-opus-4.7
base_url: '' # cleared on provider switch
api_mode: chat_completions
Auxiliary override (example — vision on gemini-flash):
auxiliary:
vision:
provider: openrouter
model: google/gemini-2.5-flash
base_url: ''
api_key: ''
timeout: 120
extra_body: {}
download_timeout: 30
Auxiliary on auto (default):
auxiliary:
compression:
provider: auto
model: ''
base_url: ''
# ... other fields unchanged
provider: auto with model: '' tells Hermes to use the main model for that task, while still honoring fallback policy if the main route cannot serve the auxiliary call.
Optional task-specific fallback chains live under the same auxiliary task:
auxiliary:
title_generation:
provider: auto
model: ''
fallback_chain:
- provider: openrouter
model: inclusionai/ring-2.6-1t:free
When fallback_chain is absent, auto uses the top-level fallback_providers chain before the built-in auxiliary discovery chain.
Per-provider request options
Provider entries (providers.<name> in the providers: dict, or items in the legacy custom_providers list) accept two knobs that shape how Hermes talks to the endpoint:
extra_headers — a mapping of extra HTTP headers attached to every LLM request routed to that provider's base URL. They are applied last, after URL/profile defaults and user header overrides, so they survive credential swaps and client rebuilds. Useful for Cloudflare Access service tokens, proxy auth, or custom bearer schemes:
providers:
my-gateway:
api: https://llm.internal.example.com/v1
api_key: sk-...
extra_headers:
CF-Access-Client-Id: "xxxx.access"
CF-Access-Client-Secret: "yyyy"
Header values routinely carry credentials — Hermes never logs them. extra_headers applies to OpenAI-compatible routes; the anthropic_messages and bedrock_converse API modes do not use it.
discover_models — set to false (default true) to skip querying the endpoint's /models listing and use only the models you configured on the entry. Handy for gateways whose model listing is slow, unreliable, or noisy:
providers:
my-gateway:
api: https://llm.internal.example.com/v1
discover_models: false
models:
- my-finetune-v2
- my-finetune-v1
With discovery off, the model picker (hermes model, /model) shows the configured list instead of a live probe.
Older configs used a top-level custom_providers: list (with base_url instead of api). It still works and is auto-migrated to the providers: dict on hermes update (config v12).
When does it take effect?
- CLI (
hermes chat): nexthermes chatinvocation. - Gateway (Telegram, Discord, Slack, etc.): next new session. Existing sessions keep their model. Restart the gateway (
hermes gateway restart) if you want to force all sessions to pick up the change. - Dashboard chat tab (
/chat): next new PTY. The currently-open chat keeps its model — use/modelinside it to hot-swap.
Changes never invalidate prompt caches on running sessions. That's deliberate: swapping the main model inside a session requires a cache reset (the system prompt contains model-specific content), and we reserve that for the explicit /model slash command inside chat.
Troubleshooting
"No authenticated providers" in the picker
Hermes lists a provider only if it has a working credential. Check Keys in the sidebar — you should see one of: an API key, a successful OAuth, or a custom endpoint URL. If the provider you want isn't there, run hermes setup to wire it up, or go to Keys and add the env var.
Main model didn't change in my running chat
Expected. The dashboard writes config.yaml, which new sessions read. The currently-open chat is a live agent process — it keeps whatever model it was spawned with. Use /model <name> inside the chat to hot-swap that specific session.
Auxiliary override "didn't take effect"
Three things to check:
- Did you start a new session? Existing chats don't re-read config.
- Is
providerset to something other thanauto? If the field showsauto, the task is still using your main model. Click Change and pick a real provider. - Is the provider authenticated? If you assigned
minimaxto a task but don't have a MiniMax API key, that task falls back to the openrouter default and logs a warning inagent.log.
I picked a model but Hermes switched providers on me
On OpenRouter (or any aggregator), bare model names resolve within the aggregator first. So claude-sonnet-4 on OpenRouter becomes anthropic/claude-sonnet-4.6, staying on your OpenRouter auth. But if you typed claude-sonnet-4 on a native Anthropic auth, it would stay as claude-sonnet-4-6. If you see an unexpected provider switch, check that your current provider is what you expect — the picker always shows the current main at the top of the dialog.
Alternative methods
CLI slash command
Inside any hermes chat session:
/model gpt-5.4 --provider openrouter # session-only
/model gpt-5.4 --provider openrouter --global # also persists to config.yaml
/model claude-opus-4.6 --once # next turn only, then auto-restores
--global does the same thing the dashboard's Change button does, plus it switches the running session in-place.
--once switches for a single turn and restores the previous model afterward — on success, error, or interrupt alike. Nothing is persisted: a gateway restart mid-turn comes back on the original model. Useful for escalating one hard question to an expensive model ("ask Opus just this once") or dropping to a cheap model for a throwaway query.
A one-turn switch breaks the provider's prompt-cache prefix twice (switching out and back). In a long session on a cached-prefix provider (Anthropic, OpenAI), the next turn re-pays full input cost — --once wins for short sessions or cheap→expensive escalation, but a quick side question inside a long expensive session can cost more than it saves.
Custom aliases
Define your own short names for models you reach for often, then use /model <alias> in the CLI or any messaging platform. There are two equivalent formats — pick whichever fits your workflow.
Canonical (top-level model_aliases:) — full control over provider + base_url:
# ~/.hermes/config.yaml
model_aliases:
fav:
model: claude-sonnet-4.6
provider: anthropic
grok:
model: grok-4
provider: x-ai
Short string form (model.aliases.<name>: provider/model) — convenient from the shell because hermes config set only writes scalar values, but it can't carry a custom base_url:
hermes config set model.aliases.fav anthropic/claude-opus-4.6
hermes config set model.aliases.grok x-ai/grok-4
Both paths feed the same loader (hermes_cli/model_switch.py). Entries declared in model_aliases: take precedence over model.aliases: entries with the same name.
Then /model fav or /model grok in chat. User aliases shadow built-in short names (sonnet, kimi, opus, etc.). See Custom model aliases for the full reference.
hermes model subcommand
hermes model # Interactive provider + model picker (the canonical way to switch defaults)
hermes model walks you through picking a provider, authenticating (OAuth flows open a browser; API-key providers prompt for the key), and then choosing a specific model from that provider's curated catalog. The choice is written to model.provider and model.default in ~/.hermes/config.yaml.
To list providers/models without launching the picker, use the dashboard or the REST endpoints below. To inspect what the CLI will actually use right now: hermes config get model --json and hermes status.
Direct config edit
Edit ~/.hermes/config.yaml and restart whatever reads it. See the Configuration reference for the full schema.
REST API
The dashboard uses three endpoints. Useful for scripting:
# List authenticated providers + curated model lists
curl -H "X-Hermes-Session-Token: $TOKEN" http://localhost:PORT/api/model/options
# Read current main + auxiliary assignments
curl -H "X-Hermes-Session-Token: $TOKEN" http://localhost:PORT/api/model/auxiliary
# Set the main model
curl -X POST -H "Content-Type: application/json" -H "X-Hermes-Session-Token: $TOKEN" \
-d '{"scope":"main","provider":"openrouter","model":"anthropic/claude-opus-4.7"}' \
http://localhost:PORT/api/model/set
# Override a single auxiliary task
curl -X POST -H "Content-Type: application/json" -H "X-Hermes-Session-Token: $TOKEN" \
-d '{"scope":"auxiliary","task":"vision","provider":"openrouter","model":"google/gemini-2.5-flash"}' \
http://localhost:PORT/api/model/set
# Assign one model to every auxiliary task
curl -X POST -H "Content-Type: application/json" -H "X-Hermes-Session-Token: $TOKEN" \
-d '{"scope":"auxiliary","task":"","provider":"openrouter","model":"google/gemini-2.5-flash"}' \
http://localhost:PORT/api/model/set
# Reset all auxiliary tasks to auto
curl -X POST -H "Content-Type: application/json" -H "X-Hermes-Session-Token: $TOKEN" \
-d '{"scope":"auxiliary","task":"__reset__","provider":"","model":""}' \
http://localhost:PORT/api/model/set
The session token is injected into the dashboard HTML at startup and rotates on every server restart. Grab it from the browser devtools (window.__HERMES_SESSION_TOKEN__) if you're scripting against a running dashboard.