Kanban tutorial
A walkthrough of the four use-cases the Hermes Kanban system was designed for, with the dashboard open in a browser. If you haven't read the Kanban overview yet, start there — this assumes you know what a task, run, assignee, and dispatcher are.
Setup
hermes kanban init # optional; first `hermes kanban <anything>` auto-inits
hermes dashboard # opens http://127.0.0.1:9119 in your browser
# click Kanban in the left nav
The dashboard is the most comfortable place for you to watch the system. Agent workers the dispatcher spawns never see the dashboard or the CLI — they drive the board through a dedicated kanban_* toolset (kanban_show, kanban_list, kanban_complete, kanban_block, kanban_heartbeat, kanban_comment, kanban_attach, kanban_attach_url, kanban_attachments, kanban_create, kanban_link, kanban_unblock). All three surfaces — dashboard, CLI, worker tools — route through the same per-board SQLite DB (~/.hermes/kanban.db for the default board, ~/.hermes/kanban/boards/<slug>/kanban.db for any board you create later), so each board is consistent no matter which side of the fence a change came from.
This tutorial uses the default board throughout. If you want multiple isolated queues (one per project / repo / domain), see Boards (multi-project) in the overview — the same CLI / dashboard / worker flows apply per board, and workers physically cannot see tasks on other boards.
Throughout the tutorial, code blocks labelled bash are commands you run. Code blocks labelled # worker tool calls are what the spawned worker's model emits as tool calls — shown here so you can see the loop end-to-end, not because you'd ever run them yourself.
The board at a glance
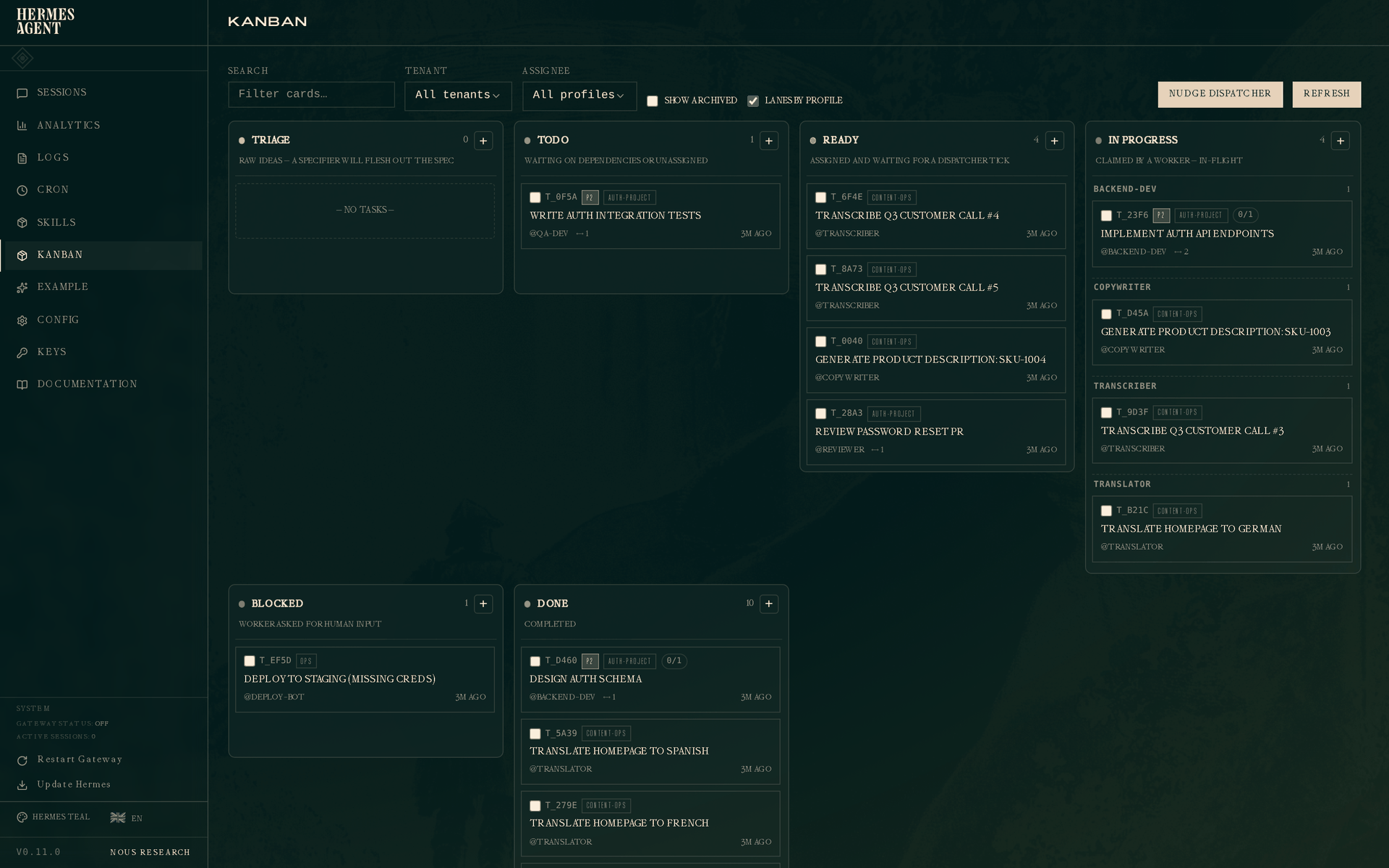
Six columns, left to right:
- Triage — raw ideas. By default the dispatcher auto-runs the decomposer on tasks here: the built-in decomposer uses
auxiliary.kanban_decomposer, reads your profile roster + descriptions, and produces a graph of child tasks routed to the best-fit specialists. The original task is held alive as the parent so its assignee (kanban.orchestrator_profile, or the active default profile when unset) wakes back up to judge completion when everything finishes. Flip the Orchestration: Auto/Manual pill at the top of the kanban page to switch modes. In Manual mode click ⚗ Decompose on a card, or runhermes kanban decompose <id>//kanban decompose <id>. For single tasks that don't need fan-out, ✨ Specify does a one-shot spec rewrite (goal, approach, acceptance criteria) and promotes totodo. Configure the models underauxiliary.kanban_decomposerandauxiliary.triage_specifierinconfig.yaml. See Auto vs Manual orchestration in the main Kanban guide. - Todo — created but waiting on dependencies, or not yet assigned.
- Ready — assigned and waiting for the dispatcher to claim.
- In progress — a worker is actively running the task. With "Lanes by profile" on (the default), this column sub-groups by assignee so you can see at a glance what each worker is doing.
- Blocked — a worker asked for human input, or the circuit breaker tripped.
- Done — completed.
The top bar has filters for search, tenant, and assignee, plus a Lanes by profile toggle and a Nudge dispatcher button that runs one dispatch tick right now instead of waiting for the daemon's next interval. Clicking any card opens its drawer on the right.
Flat view
If the profile lanes are noisy, toggle "Lanes by profile" off and the In Progress column collapses to a single flat list ordered by claim time:
Story 1 — Solo dev shipping a feature
You're building a feature. Classic flow: design a schema, implement the API, write the tests. Three tasks with parent→child dependencies.
SCHEMA=$(hermes kanban create "Design auth schema" \
--assignee backend-dev --tenant auth-project --priority 2 \
--body "Design the user/session/token schema for the auth module." \
--json | jq -r .id)
API=$(hermes kanban create "Implement auth API endpoints" \
--assignee backend-dev --tenant auth-project --priority 2 \
--parent $SCHEMA \
--body "POST /register, POST /login, POST /refresh, POST /logout." \
--json | jq -r .id)
hermes kanban create "Write auth integration tests" \
--assignee qa-dev --tenant auth-project --priority 2 \
--parent $API \
--body "Cover happy path, wrong password, expired token, concurrent refresh."
Because API has SCHEMA as its parent, and tests has API as its parent, only SCHEMA starts in ready. The other two sit in todo until their parents complete. This is the dependency promotion engine doing its job — no other worker will pick up the test-writing until there's an API to test.
On the next dispatcher tick (60s by default, or immediately if you hit Nudge dispatcher) the backend-dev profile spawns as a worker with HERMES_KANBAN_TASK=$SCHEMA in its env. Here's what the worker's tool-call loop looks like from inside the agent:
# worker tool calls — NOT commands you run
kanban_show()
# → returns title, body, worker_context, parents, prior attempts, comments
# (worker reads worker_context, uses terminal/file tools to design the schema,
# write migrations, run its own checks, commit — the real work happens here)
kanban_heartbeat(note="schema drafted, writing migrations now")
kanban_complete(
summary="users(id, email, pw_hash), sessions(id, user_id, jti, expires_at); "
"refresh tokens stored as sessions with type='refresh'",
metadata={
"changed_files": ["migrations/001_users.sql", "migrations/002_sessions.sql"],
"decisions": ["bcrypt for hashing", "JWT for session tokens",
"7-day refresh, 15-min access"],
},
)
kanban_show defaults task_id to $HERMES_KANBAN_TASK, so the worker doesn't need to know its own id. kanban_complete writes the summary + metadata onto the current task_runs row, closes that run, and transitions the task to done — all in one atomic hop through kanban_db.
When SCHEMA hits done, the dependency engine promotes API to ready automatically. The API worker, when it picks up, will call kanban_show() and see SCHEMA's summary and metadata attached to the parent handoff — so it knows the schema decisions without re-reading a long design doc.
Click the completed schema task on the board and the drawer shows everything:
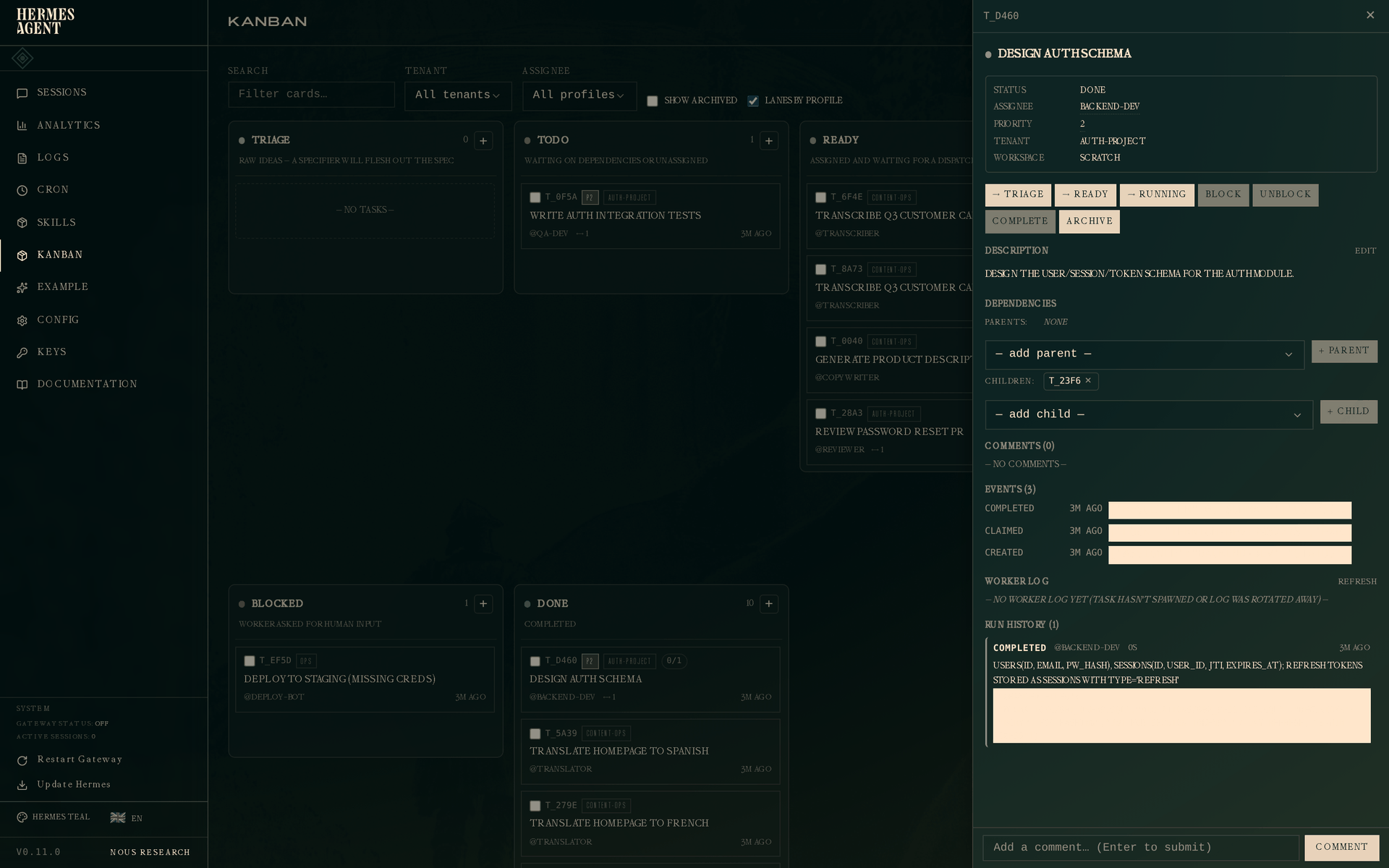
The Run History section at the bottom is the key addition. One attempt: outcome completed, worker @backend-dev, duration, timestamp, and the handoff summary in full. The metadata blob (changed_files, decisions) is stored on the run too and surfaced to any downstream worker that reads this parent.
You can inspect the same data from your terminal at any time — these commands are you peeking at the board, not the worker:
hermes kanban show $SCHEMA
hermes kanban runs $SCHEMA
# # OUTCOME PROFILE ELAPSED STARTED
# 1 completed backend-dev 0s 2026-04-27 19:34
# → users(id, email, pw_hash), sessions(id, user_id, jti, expires_at); refresh tokens ...
Story 2 — Fleet farming
You have three workers (a translator, a transcriber, a copywriter) and a pile of independent tasks. You want all three pulling in parallel and making visible progress. This is the simplest kanban use-case and the one the original design optimized for.
Create the work:
for lang in Spanish French German; do
hermes kanban create "Translate homepage to $lang" \
--assignee translator --tenant content-ops
done
for i in 1 2 3 4 5; do
hermes kanban create "Transcribe Q3 customer call #$i" \
--assignee transcriber --tenant content-ops
done
for sku in 1001 1002 1003 1004; do
hermes kanban create "Generate product description: SKU-$sku" \
--assignee copywriter --tenant content-ops
done
Start the gateway and walk away — it hosts the embedded dispatcher that picks up all three specialist profiles' tasks on the same kanban.db:
hermes gateway start
Now filter the board to content-ops (or just search for "Transcribe") and you get this:
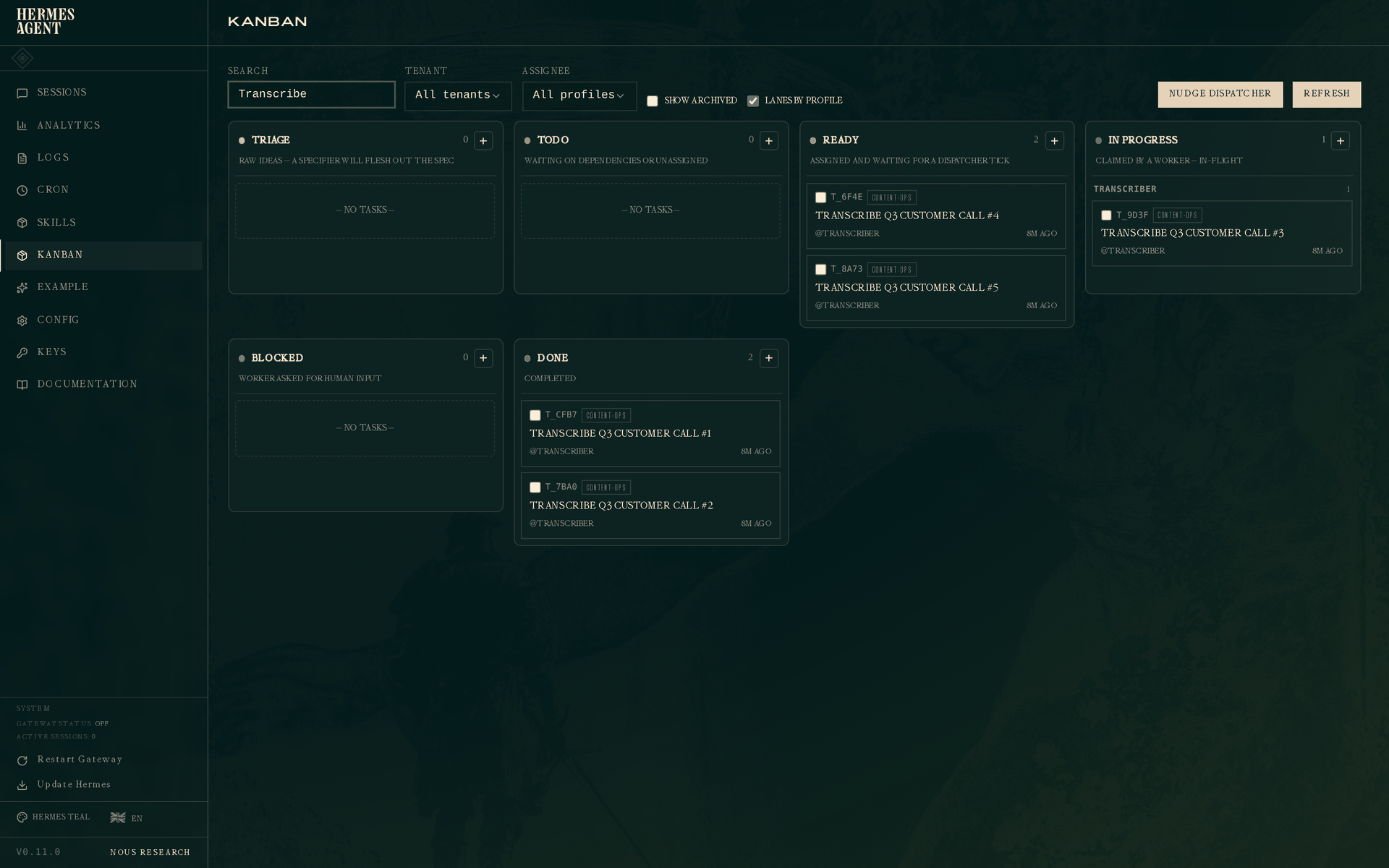
Two transcribes done, one running, two ready waiting for the next dispatcher tick. The In Progress column is grouped by profile (the "Lanes by profile" default) so you see each worker's active task without scanning a mixed list. The dispatcher will promote the next ready task to running as soon as the current one completes. With three daemons working on three assignee pools in parallel, the whole content queue drains without further human input.
Everything Story 1 said about structured handoff still applies here. A translator worker completing a call emits kanban_complete(summary="translated 4 pages, style matched existing marketing voice", metadata={"duration_seconds": 720, "tokens_used": 2100}) — useful for analytics and for any downstream task that depends on this one.
Story 3 — Role pipeline with retry
This is where Kanban earns its keep over a flat TODO list. A PM writes a spec. An engineer implements it. A reviewer rejects the first attempt. The engineer tries again with changes. The reviewer approves.
The dashboard view, filtered by auth-project:
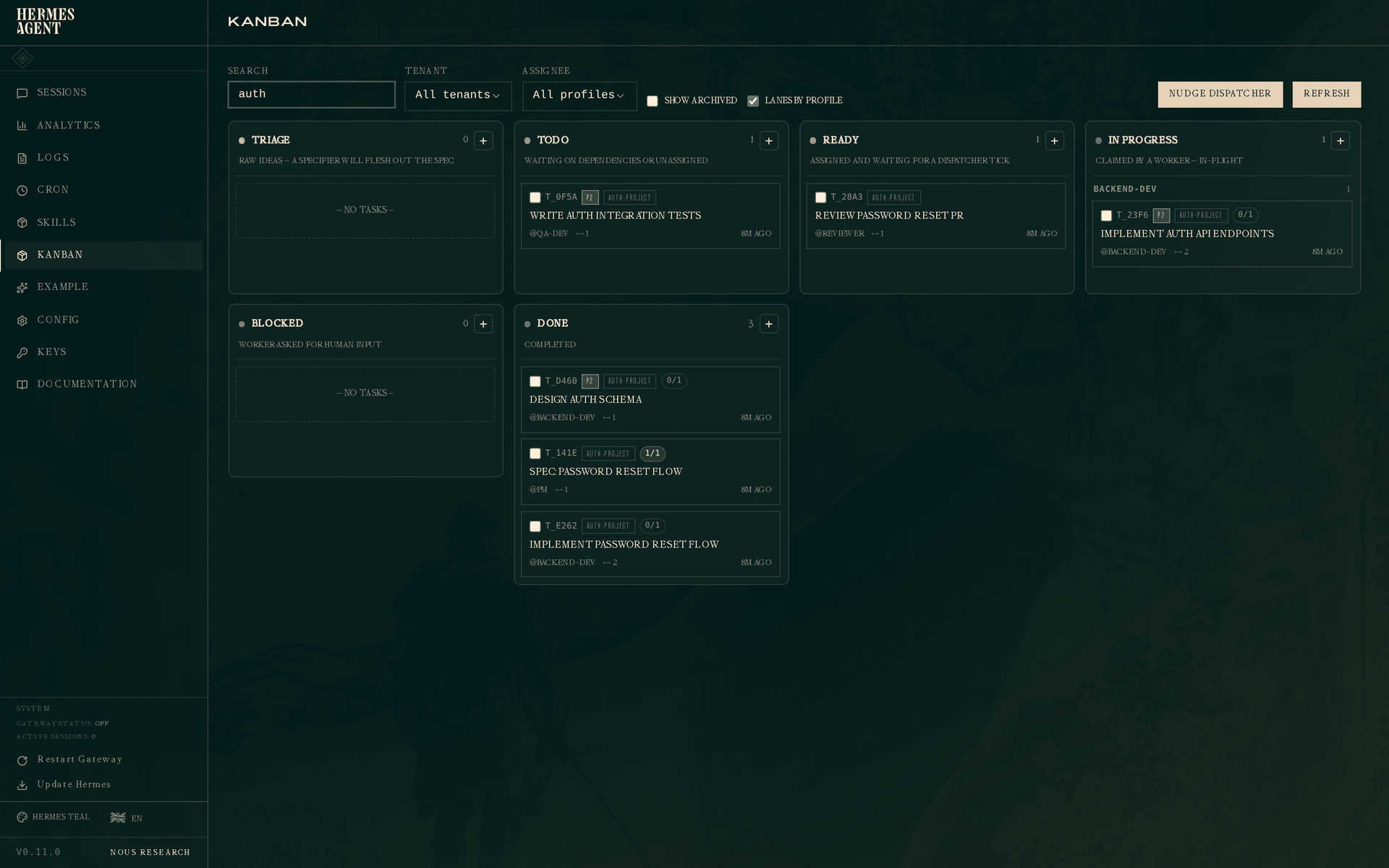
Three-stage chain visible at once: Spec: password reset flow (DONE, pm), Implement password reset flow (DONE, backend-dev), Review password reset PR (READY, reviewer). Each has its parent in green at the bottom and children as dependencies.
The interesting one is the implementation task, because it was blocked and retried. Here's the full three-agent choreography, shown as the tool calls each worker's model makes:
# --- PM worker spawns on $SPEC and writes the acceptance criteria ---
# worker tool calls
kanban_show()
kanban_complete(
summary="spec approved; POST /forgot-password sends email, "
"GET /reset/:token renders form, POST /reset applies new password",
metadata={"acceptance": [
"expired token returns 410",
"reused last-3 password returns 400 with message",
"successful reset invalidates all active sessions",
]},
)
# → $SPEC is done; $IMPL auto-promotes from todo to ready
# --- Engineer worker spawns on $IMPL (first attempt) ---
# worker tool calls
kanban_show() # reads $SPEC's summary + acceptance metadata in worker_context
# (engineer writes code, runs tests, opens PR)
# Reviewer feedback arrives — engineer decides the concerns are valid and blocks
kanban_block(
reason="Review: password strength check missing, reset link isn't "
"single-use (can be replayed within 30min)",
)
# → $IMPL transitions to blocked; run 1 closes with outcome='blocked'
Now you (the human, or a separate reviewer profile) read the block reason, decide the fix direction is clear, and unblock from the dashboard's "Unblock" button — or from the CLI / slash command:
hermes kanban unblock $IMPL
# or from a chat: /kanban unblock $IMPL
The dispatcher promotes $IMPL back to ready and, on the next tick, respawns the backend-dev worker. This second spawn is a new run on the same task:
# --- Engineer worker spawns on $IMPL (second attempt) ---
# worker tool calls
kanban_show()
# → worker_context now includes the run 1 block reason, so this worker knows
# which two things to fix instead of re-reading the whole spec
# (engineer adds zxcvbn check, makes reset tokens single-use, re-runs tests)
kanban_complete(
summary="added zxcvbn strength check, reset tokens are now single-use "
"(stored + deleted on success)",
metadata={
"changed_files": [
"auth/reset.py",
"auth/tests/test_reset.py",
"migrations/003_single_use_reset_tokens.sql",
],
"tests_run": 11,
"review_iteration": 2,
},
)
Click the implementation task. The drawer shows two attempts:
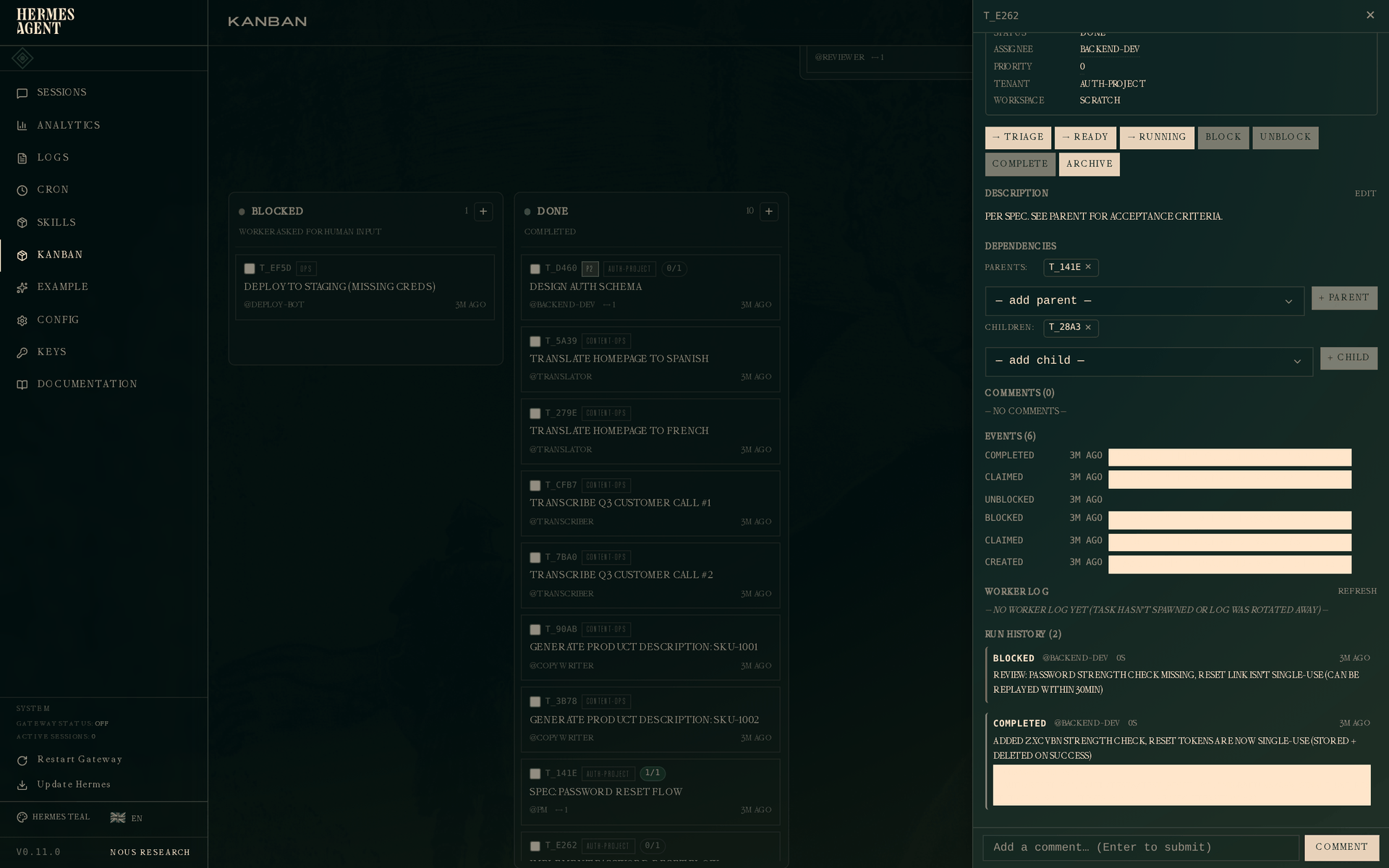
- Run 1 —
blockedby@backend-dev. The review feedback sits right under the outcome: "password strength check missing, reset link isn't single-use (can be replayed within 30min)". - Run 2 —
completedby@backend-dev. Fresh summary, fresh metadata.
Each run is a row in task_runs with its own outcome, summary, and metadata. Retry history is not a conceptual afterthought layered on top of a "latest state" task — it's the primary representation. When a retrying worker opens the task, build_worker_context shows it the prior attempts, so the second-pass worker sees why the first pass was blocked and addresses those specific findings instead of re-running from scratch.
The reviewer picks up next. When they open Review password reset PR, they see:
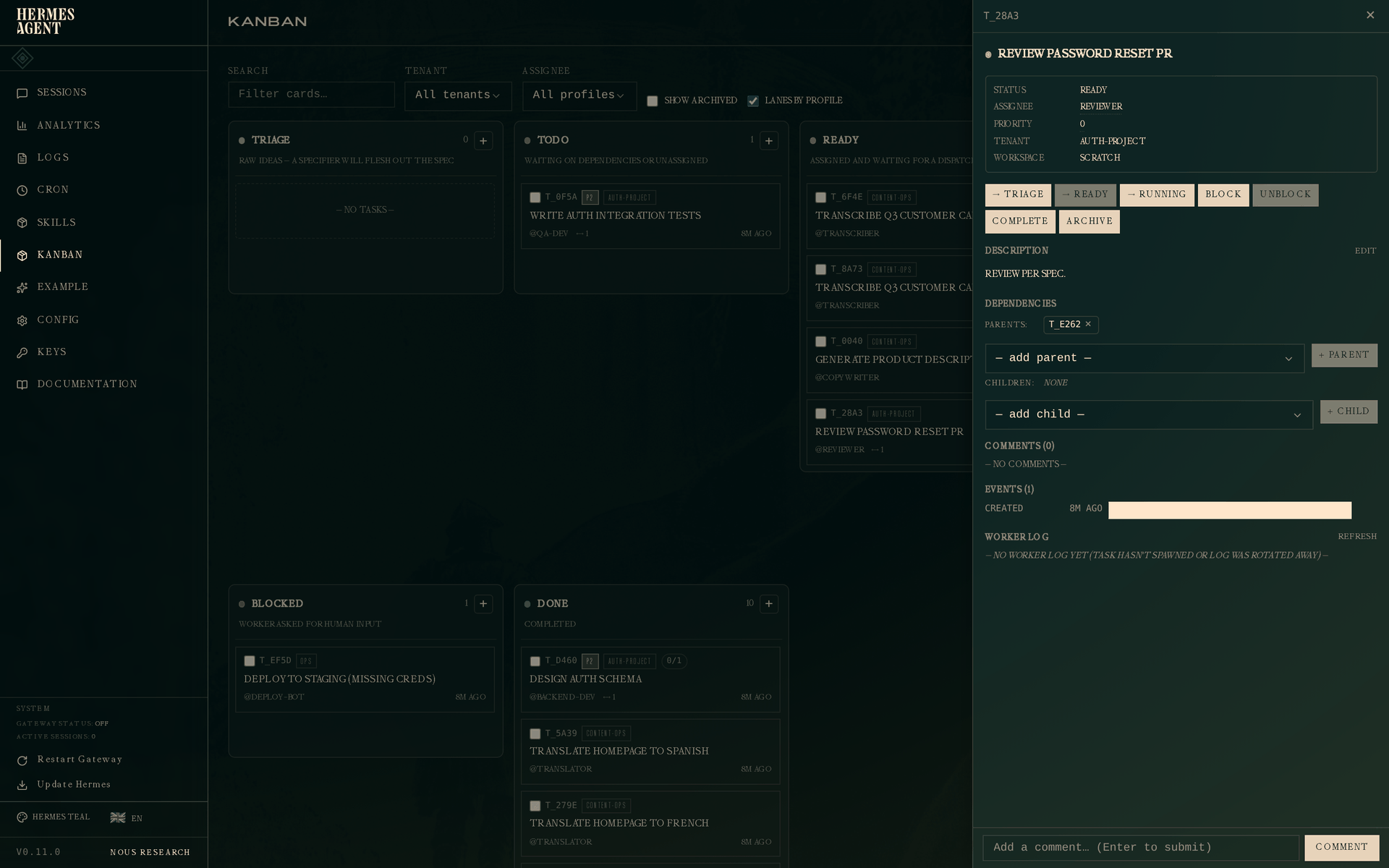
The parent link is the completed implementation. When the reviewer's worker spawns on Review password reset PR and calls kanban_show(), the returned worker_context includes the parent's most-recent-completed-run summary + metadata — so the reviewer reads "added zxcvbn strength check, reset tokens are now single-use" and has the list of changed files in hand before looking at a diff.
Story 4 — Circuit breaker and crash recovery
Real workers fail. Missing credentials, OOM kills, transient network errors. The dispatcher has two lines of defense: a circuit breaker that auto-blocks after N consecutive failures so the board doesn't thrash forever, and crash detection that reclaims a task whose worker PID went away before its TTL expired.
Circuit breaker — permanent-looking failure
A deploy task that can't spawn its worker because AWS_ACCESS_KEY_ID isn't set in the profile's environment:
hermes kanban create "Deploy to staging (missing creds)" \
--assignee deploy-bot --tenant ops \
--max-retries 3
The dispatcher tries to spawn the worker. Spawn fails (RuntimeError: AWS_ACCESS_KEY_ID not set). The dispatcher releases the claim, increments a failure counter, and tries again next tick. Because this example sets --max-retries 3, the circuit trips after three consecutive failures: the task goes to blocked with outcome gave_up. If you omit the flag, Hermes uses kanban.failure_limit (default: 2). No more retries until a human unblocks it.
Click the blocked task:
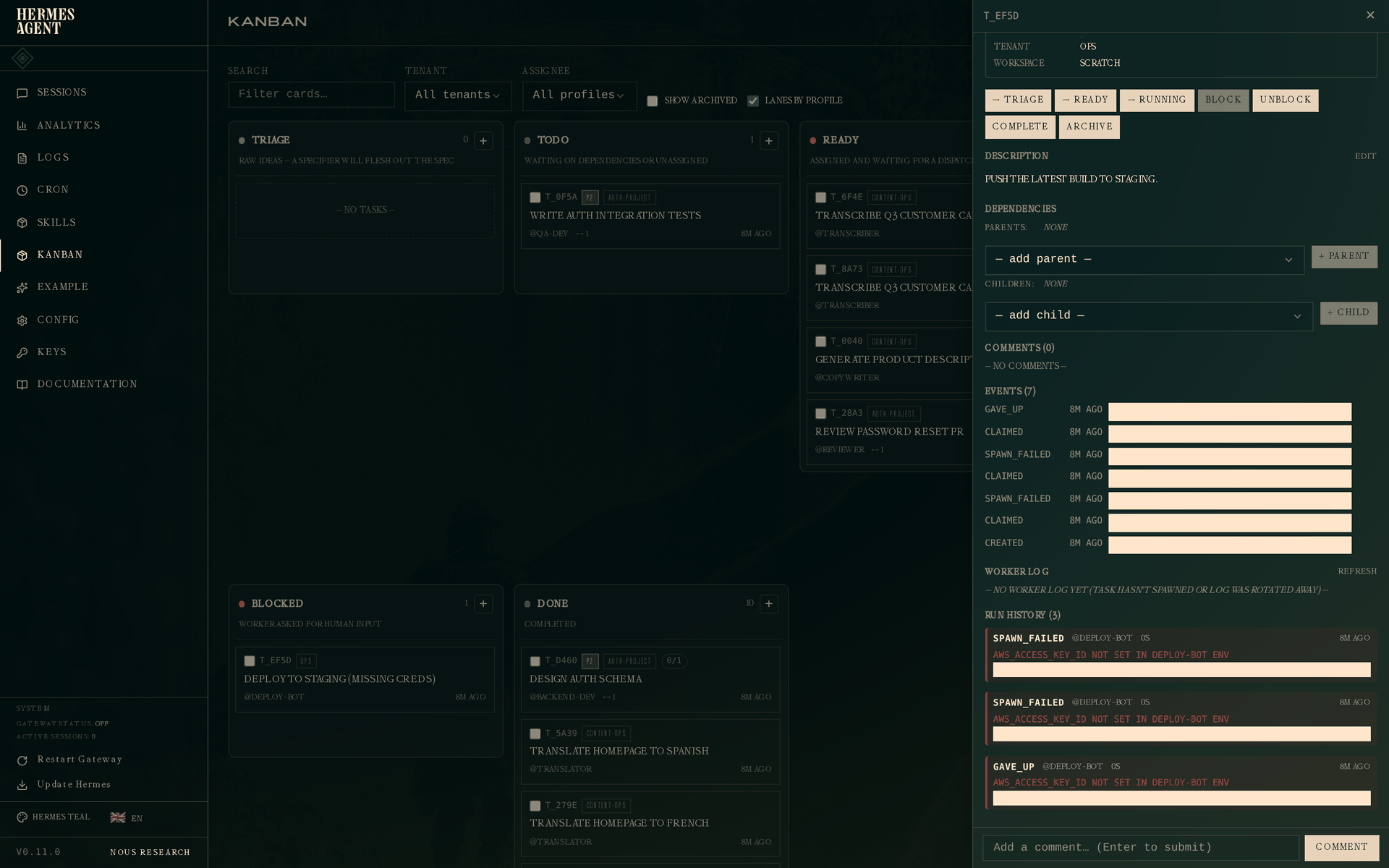
Three runs, all with the same error on the error field. The first two are spawn_failed (retryable), the third is gave_up (terminal). The event log above shows the full sequence: created → claimed → spawn_failed → claimed → spawn_failed → claimed → gave_up.
On the terminal:
hermes kanban runs t_ef5d
# # OUTCOME PROFILE ELAPSED STARTED
# 1 spawn_failed deploy-bot 0s 2026-04-27 19:34
# ! AWS_ACCESS_KEY_ID not set in deploy-bot env
# 2 spawn_failed deploy-bot 0s 2026-04-27 19:34
# ! AWS_ACCESS_KEY_ID not set in deploy-bot env
# 3 gave_up deploy-bot 0s 2026-04-27 19:34
# ! AWS_ACCESS_KEY_ID not set in deploy-bot env
If Telegram / Discord / Slack is wired in, a gateway notification fires on the gave_up event so you hear about the outage without having to check the board.
Crash recovery — worker dies mid-flight
Sometimes the spawn succeeds but the worker process dies later — segfault, OOM, systemctl stop. The dispatcher polls kill(pid, 0) and detects the dead pid; the claim releases, the task goes back to ready, and the next tick gives it to a fresh worker.
The example in the seed data is a migration that was running out of memory:
# Worker claims, starts scanning 2.4M rows, OOM kills it at ~2.3M
# Dispatcher detects dead pid, releases claim, increments attempt counter
# Retry with a chunked strategy succeeds
The drawer shows the full two-attempt history:
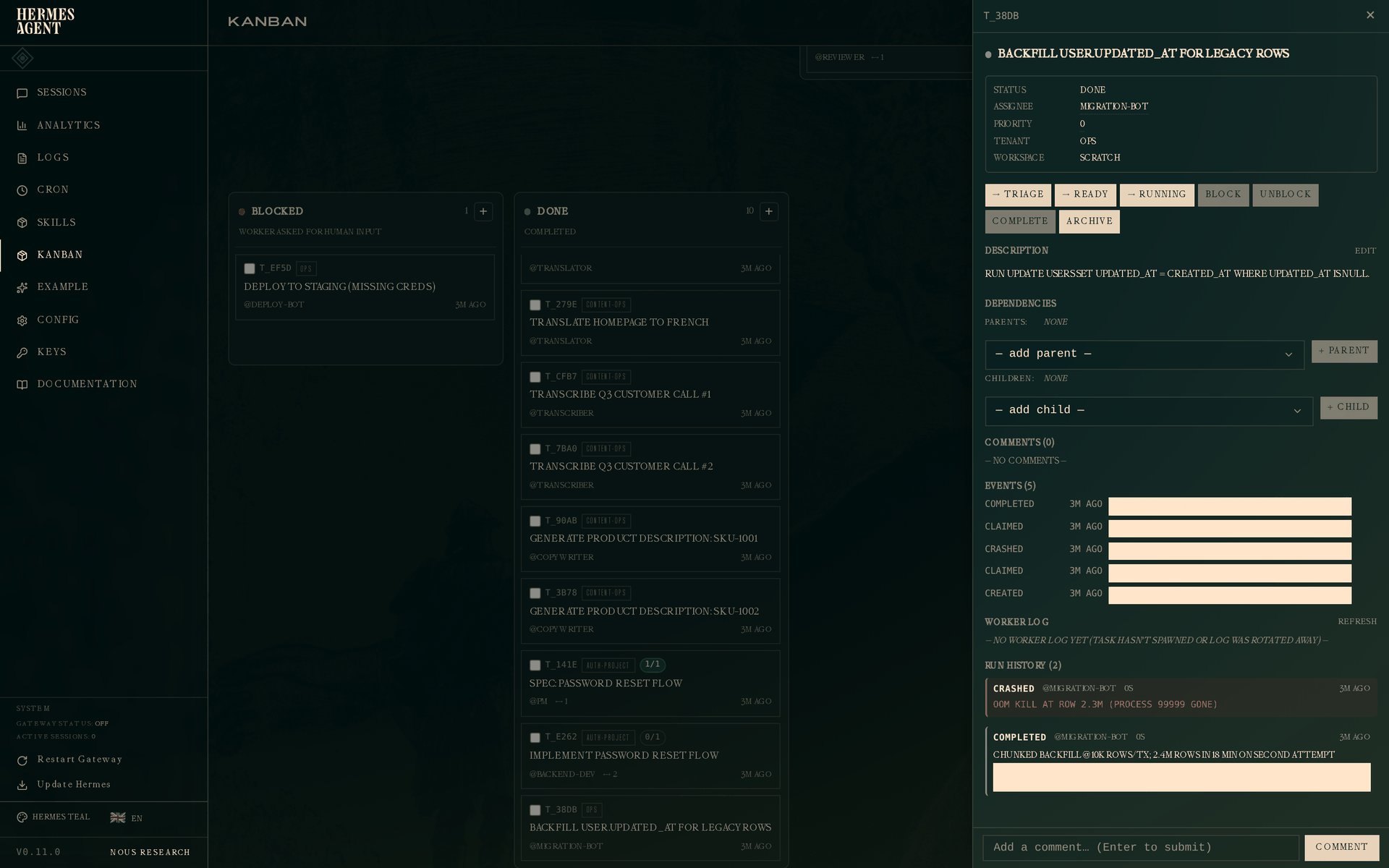
Run 1 — crashed, with the error OOM kill at row 2.3M (process 99999 gone). Run 2 — completed, with "strategy": "chunked with LIMIT + WHERE id > last_id" in its metadata. The retrying worker saw the crash of run 1 in its context and picked a safer strategy; the metadata makes it obvious to a future observer (or postmortem writer) what changed.
Structured handoff — why summary and metadata matter
In every story above, workers called kanban_complete(summary=..., metadata=...) at the end. That's not decoration — it's the primary handoff channel between stages of a workflow.
When a worker on task B is spawned and calls kanban_show(), the worker_context it gets back includes:
- B's prior attempts (previous runs: outcome, summary, error, metadata) so a retrying worker doesn't repeat a failed path.
- Parent task results — for each parent, the most-recent completed run's summary and metadata — so downstream workers see why and how the upstream work was done.
This replaces the "dig through comments and the work output" dance that plagues flat kanban systems. A PM writes acceptance criteria in the spec's metadata, and the engineer's worker sees them structurally in the parent handoff. An engineer records which tests they ran and how many passed, and the reviewer's worker has that list in hand before opening a diff.
The bulk-close guard exists because this data is per-run. hermes kanban complete a b c --summary X (you, from the CLI) is refused — copy-pasting the same summary to three tasks is almost always wrong. Bulk close without the handoff flags still works for the common "I finished a pile of admin tasks" case. The tool surface doesn't expose a bulk variant at all; kanban_complete is always single-task-at-a-time for the same reason.
Inspecting a task currently running
For completeness — here's the drawer of a task still in flight (the API implementation from Story 1, claimed by backend-dev but not yet complete):
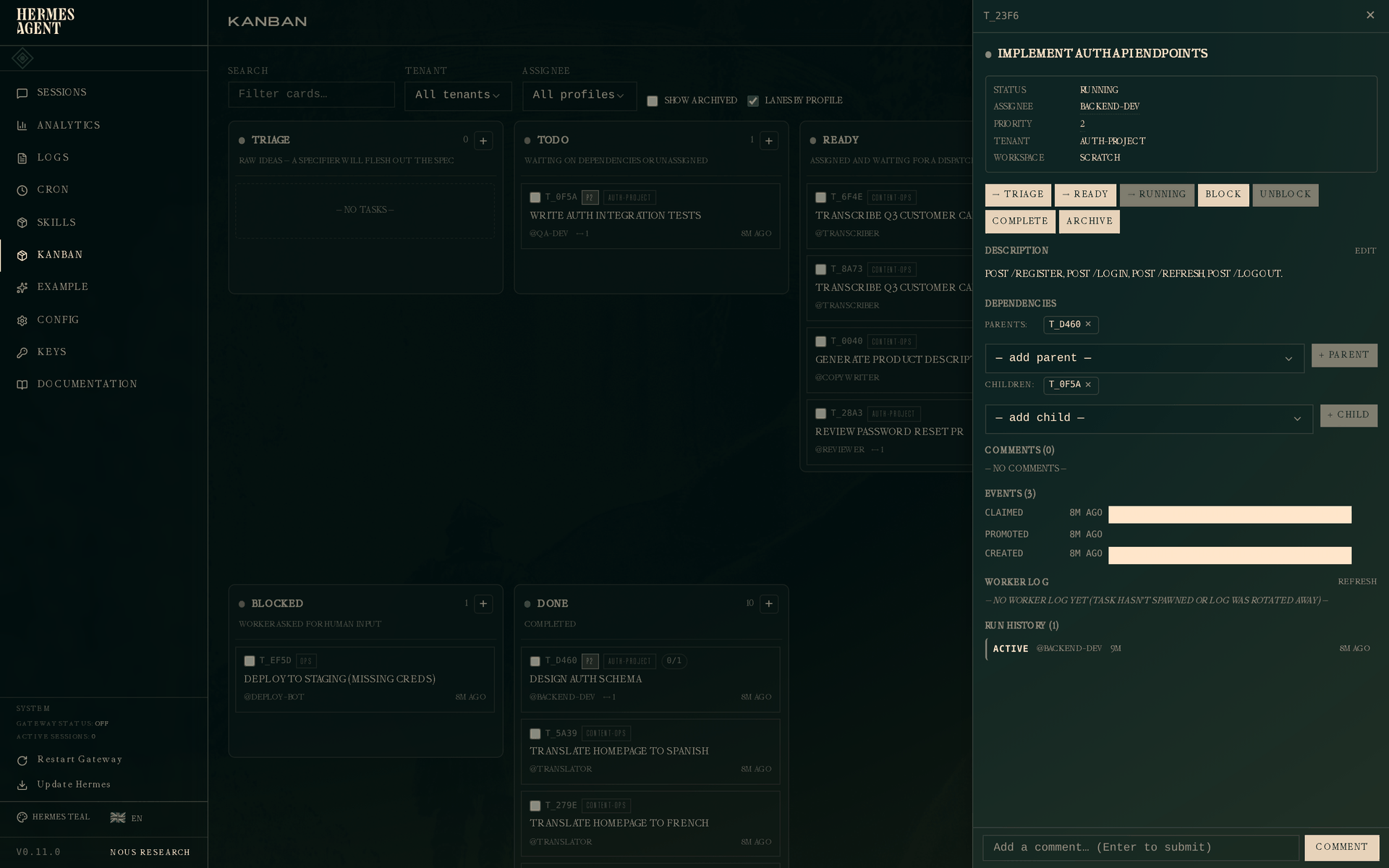
Status is Running. The active run appears in the Run History section with outcome active and no ended_at. If this worker dies or times out, the dispatcher closes this run with the appropriate outcome and opens a new one on the next claim — the attempt row never disappears.
Next steps
- Kanban overview — the full data model, event vocabulary, and CLI reference.
hermes kanban --help— every subcommand, every flag.hermes kanban watch --kinds completed,gave_up,timed_out— live stream terminal events across the whole board.hermes kanban notify-subscribe <task> --platform telegram --chat-id <id>— get a gateway ping when a specific task finishes.